NRU


Wichtig
- nach n Schritte (|) wird Referenced-Bit zurückgesetzt
- Beim Fault Page (Schreiboperation) werden zuerst die Referenced-Bit und Dirty-Bit neu (beim Erreichen von n Schritte) berechnet. → niedrigeste Bit muss ersetzt werden. z.B. (0,0)
LIFO

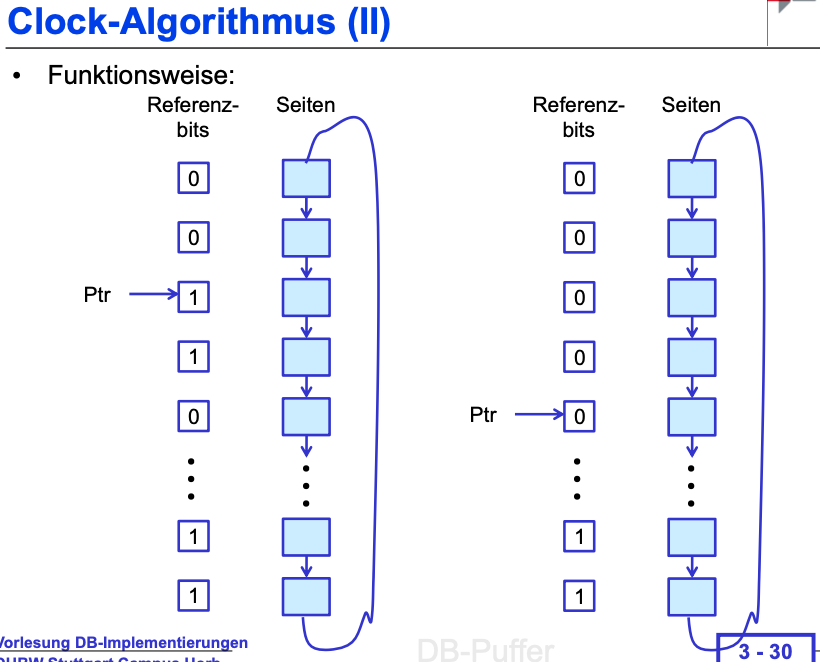
Clock-Algorithmus


Übungsaufgaben
Warum gibt es Datenbankpuffer?
Um die Leistung von Datenbanken zu verbessern, indem häufig abgerufene Daten im Hauptspeicher vorgehalten werden, anstatt bei jedem Zugriff von der Festplatte gelesen werden zu müssen.
Was ist die Zugriffslücke?
Die Zugriffslücke (“Access Gap”) beschreibt den enormen Geschwindigkeitsunterschied zwischen dem Zugriff auf den Hauptspeicher und dem Zugriff auf den Sekundärspeicher (z.B. Festplatte).
Nennen Sie fünf Seitenersetzungsverfahren!
- FIFO (First In, First Out)
- LIFO (Last In, First Out)
- LRU (Least Recently Used)
- NRU (Not Recently Used)
- Clock-Algorithmus
Erläutern Sie den Clock-Algorithmus!
Der Clock-Algorithmus verwendet einen Ringpuffer mit einem Zeiger. Jede Seite hat ein Referenzbit. Wenn eine Seite angefordert wird, wird das Referenzbit gesetzt. Der Zeiger wandert durch den Puffer. Trifft er auf eine Seite mit gesetztem Referenzbit, setzt er es auf 0 und wandert weiter. Trifft er auf eine Seite mit Referenzbit 0, wird diese Seite ersetzt.
Warum ist der LRU-Algorithmus aus Betriebssystemen in Datenbanken nicht anwendbar?
Der LRU-Algorithmus aus Betriebssystemen ist in Datenbanken nicht ideal, weil Datenbanken oft vorhersehbare Zugriffsmuster haben, die von LRU nicht optimal genutzt werden.
Erläutern Sie den LRU-k-Algorithmus!
Der LRU-k-Algorithmus berücksichtigt die letzten k Zugriffe auf eine Seite, um die Seite mit der größten k-Rückwärtsdistanz (d.h. die am längsten nicht zugegriffene Seite) auszuwählen.
Wie sieht die beste Implementierung für das Suchen im DB-Puffer aus?
Die beste Implementierung für das Suchen im Datenbankpuffer ist die Verwendung einer Hashtabelle mit Überlaufketten.